FACEGAN: Facial Attribute Controllable rEenactment GAN
Soumya Tripathy, Juho Kannala and Esa Rahtu
Accepted to WACV-2021
Code coming soon
Paper
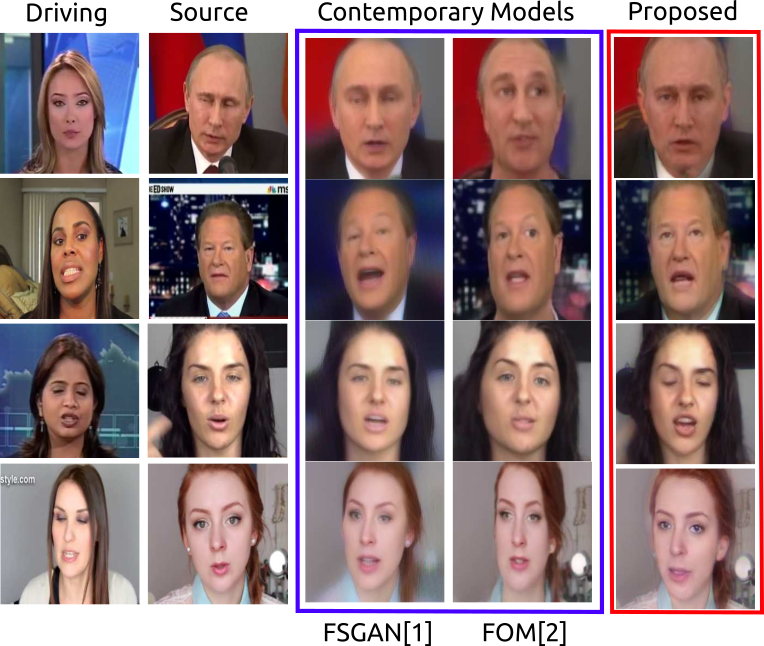
Figure 1: Examples of the face-reenactment results using the proposed FACEGAN and recent baseline works FSGAN [1] and First-Order-motion-Model (FOM) [2]. FACEGAN is able to preserve the source identity faithfully while imposing the driving pose and expression. The baselines suffer particularly in preserving the facial shape of the source.
1 Abstract
The face reenactment is a popular facial animation method where the person’s identity is taken from the source image and the facial motion from the driving image. Recent works have demonstrated high quality results by combining the facial landmark based motion representations with the generative adversarial networks. These models perform best if the source and driving images depict the same person or if the facial structures are otherwise very similar. However, if the identity differs, the driving facial structures leak to the output distorting the reenactment result. We propose a novel Facial Attribute Controllable rEenactment GAN (FACEGAN), which transfers the facial motion from the driving face via the Action Unit (AU) representation. Unlike facial landmarks, the AUs are independent of the facial structure preventing the identity leak. Moreover, AUs provide a human interpretable way to control the reenactment. FACEGAN processes background and face regions separately for optimized output quality. The extensive quantitative and qualitative comparisons show a clear improvement over the state-of-the-art in a single source reenactment task. The results are best illustrated in the reenactment video provided below.
2 Key Idea
Most recent works1, 2 use facial landmark points (key points in 3) as the representation of the facial motion (pose and expression). Although landmarks can provide strong supervision of the driving motion, they also contain the overall structure of the driving face in the form of facial contours. If the driving landmarks are directly used to animate the source face, the difference between the facial contours may lead to dramatic distortions in the output result. Therefore, the gap in the facial shapes usually leads to either losing the source identity or low photorealism as shown in figure below.
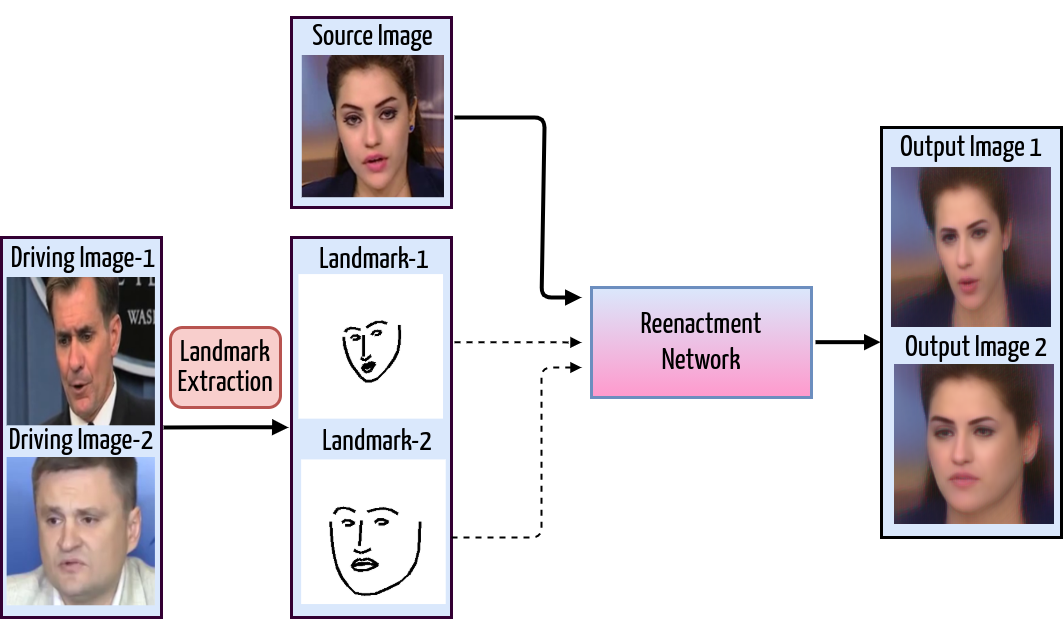
Figure 2: An illustration of the facial structure leaking problem in the landmark/keypoint based reenactment approach. The facial structure of the generated output clearly follows the shape of the driving face instead of source face as intended.
In this paper, we propose a Facial Attribute Controllable rEenactment GAN (FACEGAN), which produces high quality source reenactment from various driving pairs even with significant facial structure differences between them. Our model uses the extracted Action Units (AUs) from driving faces as the motion cues and manipulates the source face-landmarks to generate a new set of landmarks representing the desired motion with the source facial structure. This mitigates the identity leakage problem present in many recent works. Furthermore, by representing the motion cues using the action units, we provide a selective editing interface to the reenactment process. The proposed method combines the benefits of the action units (subject agnostic and interpretable) and facial landmarks (strong supervision for image generation) into a single reenactment system. The block diagram of the FACEGAN is given below and for the detail explanations of the model please refer to our paper.
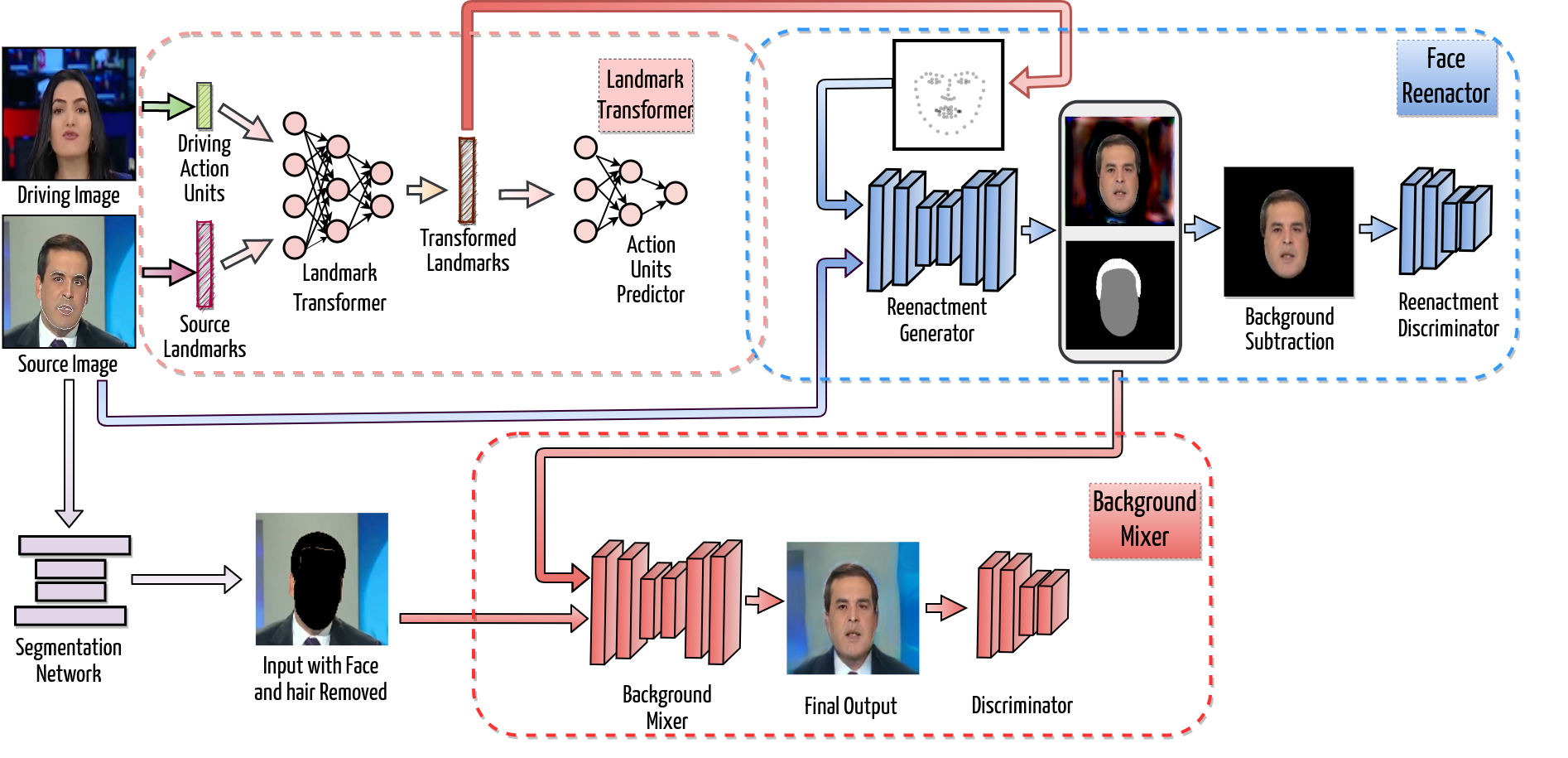
Figure 3: The overall architecture of the proposed FACEGAN contains three major blocks, namely 1. Landmark transformer, 2. Face reenactor, and 3. Background Mixer. The Landmark transformer modifies the source landmarks to include the driving face’s expression and pose, which are represented in terms of action units (AUs). The modified landmarks and the source image are provided to the Face reenactor module for producing the reenacted face. Finally, the reenacted face and the source background are combined into the output by the Background mixer module. In the training phase, we use the source and driving images from the same face track, which allows us to use the driving image as a pixel-wise ground truth of the output. However, during the inference, the source and driving may have different identities.
3 Citation
If you find this work useful in your research work then please cite us as:
@InProceedings{Tripathy_2021_WACV, author = {Tripathy, Soumya and Kannala, Juho and Rahtu, Esa}, title = {FACEGAN: Facial Attribute Controllable rEenactment GAN}, booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)}, year = {2021} }
@InProceedings{Tripathy_2020_WACV, author = {Tripathy, Soumya and Kannala, Juho and Rahtu, Esa}, title = {ICface: Interpretable and Controllable Face Reenactment Using GANs}, booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)}, month = {March}, year = {2020} }
Footnotes:
Tripathy, S., Kannala, J., Rahtu, E.: Icface: Interpretable and controllable face reenactment using gans. In: The IEEE Winter Conference on Applications of Computer Vision. (2020) 3385–3394
Zakharov, E., Shysheya, A., Burkov, E., Lempitsky, V.: Few-shot adversarial learning of realistic neural talking head models. In: Proceedings of the IEEE International Conference on Computer Vision. (2019) 9459–9468.
Nirkin, Y., Keller, Y., Hassner, T.: FSGAN: Subject agnostic face swapping and reenactment. In: Proceedings of the IEEE International Conference on Computer Vision. (2019) 7184–7193